The Chocolatey Community Repository, Made Even Sweeter with Elasticsearch!
The Chocolatey Community Repository, Made Even Sweeter with Elasticsearch!
 By Josh King |
Posted Wednesday, May 22, 2024
By Josh King |
Posted Wednesday, May 22, 2024 Have you ever searched for a package on the Chocolatey Community Repository and found yourself scratching your head at the list that was returned to you? Or perhaps even more frustratingly, tapping your foot because it is taking so long to get any results at all?
Earlier this year, in the post that started our back-to-basics series, Paul covered what the Chocolatey Community Repository is and how you’re able to use it. In this post we’re going to give you a rare peek behind the curtains at the infrastructure that powers the Chocolatey Community Repository and a recent project that saw its search functionality completely replaced.
The Need for Speed
Before diving into the recently completed project, let’s take a moment to lay out the challenges we faced with the old search system that led us to replacing it.
NOTE
I’m using the term “search” throughout this post, and this may make you think of the search bar at the top of the webpage when visiting the Chocolatey Community Repository in a browser. While that is indeed one part of the repository’s search system, it also plays an important part in the functionality of Chocolatey CLI. Any command that reaches out to the Chocolatey Community Repository, including the fundamentals like
installandupgrade, go through the search system.
Latency
The old search system wasn’t known to be performant. Unfortunately, the time to return search results was not a metric we tracked. Instead we’ll consider the overall latency experienced when using the Chocolatey Community Repository. This is average time, in seconds, it would take to respond to a request.
Over the six weeks leading up to replacing the search system the average latency was: 1.3 seconds
Do remember this is an average, meaning that many requests were responded to much faster, but on the other side of that same coin many requests were much slower. Frustrating to say the least.
Consistency
This isn’t really a statistic that can be measured, but more so a result of the architecture behind the old search system. As illustrated in the diagram below, the Chocolatey Community Repository isn’t hosted on one monolithic server and is instead powered by a number of smaller “workers”. Historically each of these workers maintained its own cache of search queries and results it had seen. As a user you had no control over which worker you connected to meaning the answer to your particular query may not be readily accessible when processing your request and so the worker has to go ask the database, cache the result, and return the answer to you.


This resulted in inconsistency when two different workers would potentially cache two different answers to a given search query. This could take the form of seeing a new version of a package and trying to install it, only to be told that that package version doesn’t exist. Why? One worker cached the fact that the previous version was the latest and won’t “see” the new version until its cache expires, and it checks with the database again.
Database Load
The local search cache mentioned above also meant that there was a lot of queries being made to the Chocolatey Community Repository’s database. If you assume there were five workers running, a given query would need to be answered five times before all of those workers had cached the answer. Repeat this for when the cache expired and the workers need to repeat those same queries again to (potentially) get an updated response. Then multiply that by over 10,000 unique packages and 200,000 package versions. I will share some graphs to help visualize the before and after of our database load following the replacement of our search system, but for now these are the raw numbers we were starting with.
- CPU Utilization: 11.88% average with spikes up to 80%.
- Incoming Network Throughput (kB/s): 409 average with spikes over 900.
- Total Storage IOPS: 297 average with spikes over 1250.
Introducing Elasticsearch
The title of this post gave away the surprise, but to address the search related challenges we were facing with the Chocolatey Community Repository, we turned to Elasticsearch.
Elasticsearch is a popular search engine that excels at full-text search and promises to provide “lightning fast search.” Sounds perfect to me.
Having settled on Elasticsearch we set about introducing it into our infrastructure. Instead of a search cache on each worker, we harvest all searchable information and index it centrally in Elasticsearch. Now each worker queries the same search cache, and this cache is the source of truth as far as the workers are concerned… there is no fall back to asking the database for a second opinion.


The keen-eyed reader will note that there is a dotted line from the workers to the database in this diagram. This is for those times when the cache needs to be updated, when, for example, a new package is pushed to the Chocolatey Community Repository.
Not All Smooth Sailing
So, problem solved, right? Nothing is ever that easy! Before we look into the results, let’s first look at some of the bumps we found in the road on this implementation journey.
A Failed Deployment
Working in Infrastructure Operations, the reality is that if I do my job right then no one should notice. When things don’t go right though, we have to do what we can to minimize the impact.
On February 19, 2024, we were all set to deploy an update to the Chocolatey Community Repository which would introduce the Elasticsearch powered search cache. We’d tested the update internally every which way we could conceive and were confident that the deployment would go off without a hitch.
And then we opened up the repository to the public.
Over a short period of time, the Chocolatey Community Repository began crawling to a halt. What we hadn’t accounted for in our testing was some of the wild, and unsupported, search queries the repository was subjected to on a persistent basis. As Elasticsearch was unable to handle these unsupported queries, the workers were helpfully redirecting them to the database which was very quickly saturated and couldn’t keep up with the load.
After some time trying to fix the issue in place, the decision was made to roll back to the previous version of the Chocolatey Community Repository while we assessed what had gone wrong and patched the code to prevent the same thing happening next time.
A few weeks later, we had a solution for handling the unsupported queries. This also led to improved testing, allowing us to better replicate real world traffic conditions. On March 24, 2024, we finally deployed the Elasticsearch enabled version of the Chocolatey Community Repository.
Long Time Issues Unmasked
With the repository now online and using the new Elasticsearch cache, several longstanding issues were uncovered that had previously been masked by the usage of a local search cache on each of the workers.
One of the these issues resulted in port exhaustion, and it stopped workers from creating new network connections. Previously, no one noticed this as the results to common searches were stored locally, so the worker could still respond to most incoming requests. Now that the workers needed to reach out to Elasticsearch? Suddenly the worker would go silent and not respond to search queries until some ports opened back up.
It’s a little embarrassing to admit that this issue had remained hidden under the old search infrastructure. But once identified, this was easily fixed.
Crossing the Finish Line
Deployment done, and teething issues addressed, did we fix the problem areas that set us on this journey in the first place? Let’s go back through them and find out!
Latency
Prior to implementing Elasticsearch, the average latency when access the Chocolatey Community Repository was 1.3 seconds and afterward this dropped to 0.6 seconds. That is over 50% of what it used to be!
This improvement was best summed up by my colleague, Gary:
Consistency
There’s not much to say here! Moving to a centralized search cache naturally means all workers are now working with exactly the same data. So responses are consistent regardless of which worker a user happens to be directed to when using the Chocolatey Community Repository.
Database Load
Finally, what happened to our database load? You’ll remember above I mentioned that the workers now consider Elasticsearch as their source of truth for search queries and there was no falling back on the database for a second opinion? Given this you’d expect to see a considerable decrease in database usage, and you’d be correct.
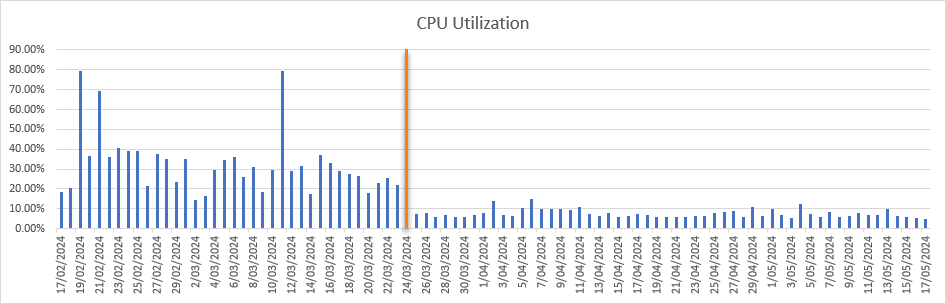
CPU Utilization
This dropped from an average of 11.88% to 5.52%, and the spikes plummeted from up to 80% down to just under 15%.
This is such a huge drop in CPU usage that we could consider reducing the size of the compute that this database runs on. That wasn’t the goal of this project, but is certainly a nice side benefit.
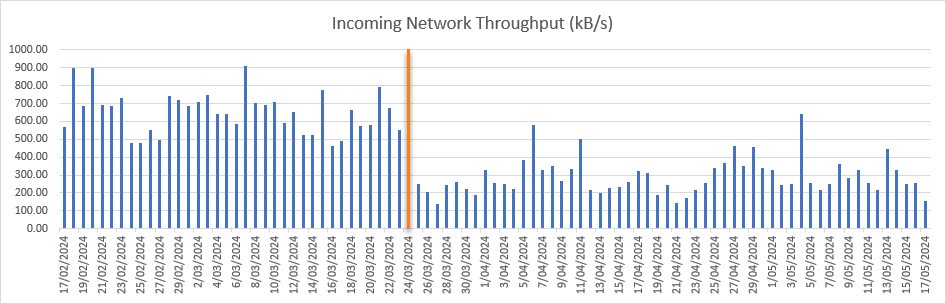
Incoming Network Throughput
Previously this was an average of 409 kB/s and is now 158 kB/s, with the spikes dropping from 900 kB/s to 644 kB/s.
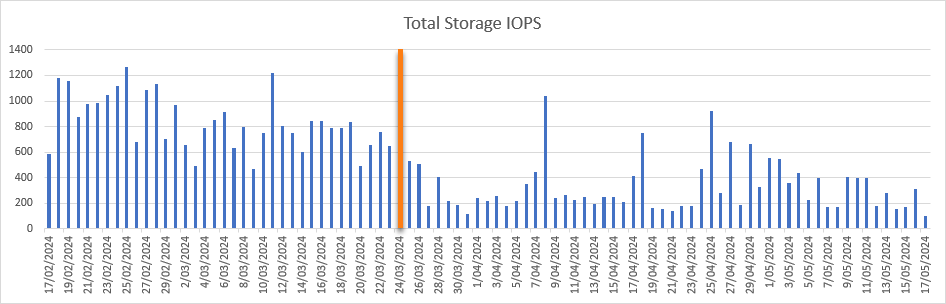
Total Storage IOPS
Finally, storage IOPS saw a similar decrease, from an average of 297 to 126, and spikes of 1250 decreasing to 1042.
Wrap Up
So there we have it, the journey towards implementing Elasticsearch on the Chocolatey Community Repository. While it wasn’t necessarily a smooth ride getting there, the end result has been amazing. I hope you’ve noticed, and benefitted from, the improved search performance.
If you’ve got any questions about this post, the Chocolatey Community Repository, or Chocolatey in general, please reach out to us on our Community Hub!
Popular Tags
- #news 74 Number of post with tag news
- #press release 58 Number of post with tag press release
- #chocolatey for business 49 Number of post with tag chocolatey for business
- #packaging 23 Number of post with tag packaging
- #open source 18 Number of post with tag open source
- #community 16 Number of post with tag community
- #tutorial 16 Number of post with tag tutorial
- #chocolatey community repository 13 Number of post with tag chocolatey community repository
- #12 days of Chocolatey 2023 12 Number of post with tag 12 days of Chocolatey 2023
- #podcast 12 Number of post with tag podcast




